
OpenAI is dedicated to making intelligence broadly accessible. Today, they are announcing GPT-4o mini, their most cost-efficient small model. OpenAI anticipates that GPT-4o mini will significantly expand the range of AI applications by making intelligence much more affordable. GPT-4o mini scores 82% on MMLU and currently outperforms GPT-4 in chat preferences on the LMSYS leaderboard. It is priced at 15 cents per million input tokens and 60 cents per million output tokens, making it an order of magnitude more affordable than previous frontier models and over 60% cheaper than GPT-3.5 Turbo.
GPT-4o mini enables a broad range of tasks with its low cost and latency. These include applications that chain or parallelize multiple model calls (e.g., calling multiple APIs), provide a large volume of context to the model (e.g., full code base or conversation history), or interact with customers through fast, real-time text responses (e.g., customer support chatbots).
Currently, GPT-4o mini supports text and vision in the API, with future plans to support text, image, video, and audio inputs and outputs. The model has a context window of 128K tokens and knowledge up to October 2023. Thanks to the improved tokenizer shared with GPT-4o, handling non-English text is now even more cost-effective.
As a small model with superior textual intelligence and multimodal reasoning, GPT-4o mini surpasses GPT-3.5 Turbo and other small models on academic benchmarks across both textual intelligence and multimodal reasoning. It supports the same range of languages as GPT-4o and demonstrates strong performance in function calling, enabling developers to build applications that fetch data or take actions with external systems. It also offers improved long-context performance compared to GPT-3.5 Turbo.
GPT-4o mini Eval Benchmark
GPT-4o mini has been evaluated across several key benchmarks:
- Reasoning tasks: GPT-4o mini outperforms other small models in reasoning tasks involving both text and vision, scoring 82.0% on MMLU, a textual intelligence and reasoning benchmark, compared to 77.9% for Gemini Flash and 73.8% for Claude Haiku.
- Math and coding proficiency: GPT-4o mini excels in mathematical reasoning and coding tasks, outperforming previous small models on the market. On MGSM, which measures math reasoning, GPT-4o mini scored 87.0%, compared to 75.5% for Gemini Flash and 71.7% for Claude Haiku. GPT-4o mini also scored 87.2% on HumanEval, a measure of coding performance, compared to 71.5% for Gemini Flash and 75.9% for Claude Haiku.
- Multimodal reasoning: GPT-4o mini demonstrates strong performance on MMMU, a multimodal reasoning evaluation, scoring 59.4% compared to 56.1% for Gemini Flash and 50.2% for Claude Haiku.

As part of OpenAI’s model development process, they collaborated with a select group of trusted partners to better understand the use cases and limitations of GPT-4o mini. Companies like Ramp and Superhuman found GPT-4o mini to perform significantly better than GPT-3.5 Turbo for tasks such as extracting structured data from receipt files and generating high-quality email responses when provided with thread history.
Built-in Safety Measures
Safety is integrated into OpenAI’s models from the beginning and reinforced at every step of the development process. During pre-training, they filter out information that should not be learned or output by the models, such as hate speech, adult content, sites that primarily aggregate personal information, and spam. In post-training, techniques like reinforcement learning with human feedback (RLHF) are used to align the model’s behavior with their policies, improving the accuracy and reliability of the models’ responses.
GPT-4o mini includes the same safety mitigations as GPT-4o, carefully assessed using both automated and human evaluations according to OpenAI’s Preparedness Framework and voluntary commitments. More than 70 external experts in fields like social psychology and misinformation tested GPT-4o to identify potential risks. These risks have been addressed, and the details will be shared in the forthcoming GPT-4o system card and Preparedness scorecard. Insights from these expert evaluations have improved the safety of both GPT-4o and GPT-4o mini.
Building on these learnings, OpenAI’s teams worked to further enhance the safety of GPT-4o mini using new techniques informed by their research. GPT-4o mini in the API is the first model to apply the instruction hierarchy method, which helps improve the model’s resistance to jailbreaks, prompt injections, and system prompt extractions, making the model’s responses more reliable and safer for use in large-scale applications.
OpenAI will continue to monitor the use of GPT-4o mini and improve the model’s safety as new risks are identified.
Availability and Pricing
GPT-4o mini is now available as a text and vision model in the Assistants API, Chat Completions API, and Batch API. Developers pay 15 cents per million input tokens and 60 cents per million output tokens, roughly equivalent to 2500 pages in a standard book. Fine-tuning for GPT-4o mini will be rolled out in the coming days.
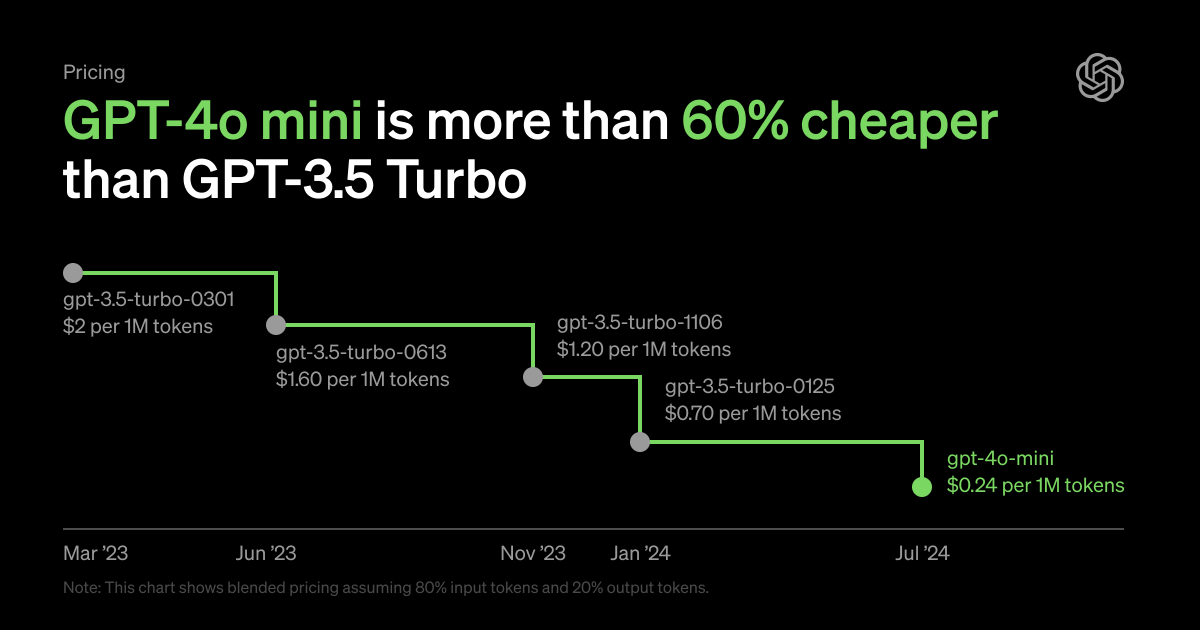
In ChatGPT, Free, Plus, and Team users will have access to GPT-4o mini starting today, replacing GPT-3.5. Enterprise users will also gain access starting next week, aligning with OpenAI’s mission to make the benefits of AI accessible to all.
What’s Next
In recent years, OpenAI has witnessed remarkable advancements in AI intelligence paired with substantial reductions in cost. For example, the cost per token of GPT-4o mini has dropped by 99% since the introduction of text-davinci-003, a less capable model, in 2022. OpenAI is committed to continuing this trajectory of driving down costs while enhancing model capabilities.
OpenAI envisions a future where models are seamlessly integrated into every app and website. GPT-4o mini is paving the way for developers to build and scale powerful AI applications more efficiently and affordably. The future of AI is becoming more accessible, reliable, and embedded in daily digital experiences, and OpenAI is excited to continue leading the way.
Read other articles: