-

FrontierMath
Today EpochAI launching FrontierMath, a benchmark for evaluating advanced mathematical reasoning in AI. They collaborated with 60+ leading mathematicians to create hundreds of original, exceptionally challenging math problems, of which current AI systems solve less than 2%. Existing math benchmarks like GSM8K and MATH are approaching saturation, with AI models scoring over 90%—partly due to…
-

DeepMind released AlphaFold 3 inference codebase
Wohoo! DeepMind released AlphaFold 3 inference codebase, model weights and an on-demand server! AlphaFold can generate highly accurate biomolecular structure predictions containing proteins, DNA, RNA, ligands, ions, and also model chemical modifications for proteins and nucleic acids in one platform. The model weights require you to fill a Google Form and wait for 3-4 business…
-
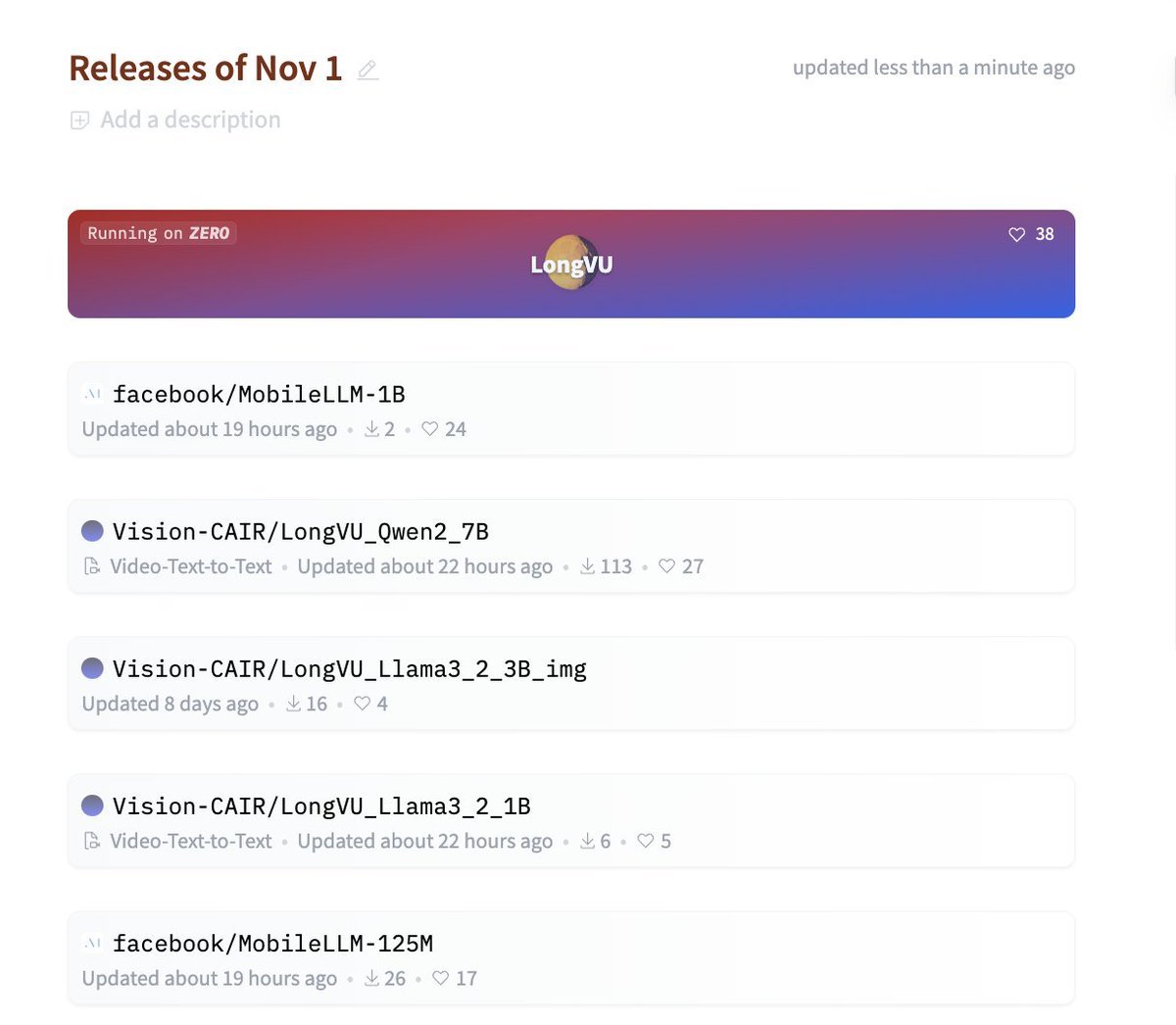
Gen AI News [November 1st, 2024]
Another great week in open ML!Here’s a small recap by @mervenoyann. Model releases ⏯️ Video Language Models @AIatMeta released LongVU, a new family of state-of-the-art long video LM models based on DINOv2, SigLIP, Qwen2 and Llama 3.2 💬 Small language models @huggingface released SmolLM2, a new family of smol language models with Apache 2.0 license…
-

Food Photography with Generative AI
How create hyper realistic food photography with Generative AI in 4k resolution ready to print (4,736 x 3,520 px). Step-by-step tutorial below. his is tutorial 1/20 of the Freepik’s Mystic exploration series @javilopen planning to do in which he will cover the main categories of image generation that any professional might need. Follow Javi at…
-

LlamaParse Premium
LlamaParse premium is the best document parser out there for your context-augmented LLM application. It can handle complex slide decks, diagrams, multi-table Excel sheets, interleaving scanned document text, and any other document type with lots of text, tables, and visual elements. Dev Team spent a lot of effort to reduce the cost! Excited to announce…
-

Nvidia Nemotron 51B
Nvidia has just announced the release of Nemotron 51B, and it’s set to redefine AI model performance across the board. This new model is 220% faster and capable of handling 400% more workload than its predecessor, Llama 3.1 70B, making it a significant leap in terms of both speed and scalability. Better yet, it’s permissively…
-

AI NEWS [Mon Sep 16, 2024]
AI NEWS: The “Godmother of AI” just launched World Labs, teaching AI to create and understand 3D worlds. Plus, more developments from OpenAI, Tencent, Runway, Google, and Meta. Here’s everything that happened in AI over the weekend. Fei-Fei Li announced a new startup Fei-Fei Li announced a new startup, World Labs, to develop AI models…
-

Pixtral 12B (pixtral-12b-240910)
Mistral released Pixtral 12B Vision Language Model (pixtral-12b-240910). Some notes on the release below. Installation Mistral common has image support! You can now pass images and URLs alongside text into the user message. To use the model checkpoint: Images You can encode images as follows: Image URLs You can pass image url which will be…
-
Workspaces – Anthropic API Console
Anthropic has introduced Workspaces in the Anthropic API Console to assist developers in efficiently managing multiple Claude deployments. These Workspaces serve as unique environments that allow for the organization of resources, the streamlining of access controls, and the setting of custom spend and rate limits at a more granular level. For developers deploying Claude across…
-

LLaVA V1.5 7B on Groq
LLaVA (Large Language and Vision Assistant) is an open-source multimodal chatbot designed to follow instructions across different modes of communication. It is developed by fine-tuning the LLaMA/Vicuna language models on data generated by GPT, enabling it to understand and generate both text and visual information. Built on the transformer architecture, LLaVA operates as an auto-regressive…