
DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL. DeepSeek VL2 excels across a range of tasks, such as visual question answering, optical character recognition, document, table, and chart comprehension, as well as visual grounding.
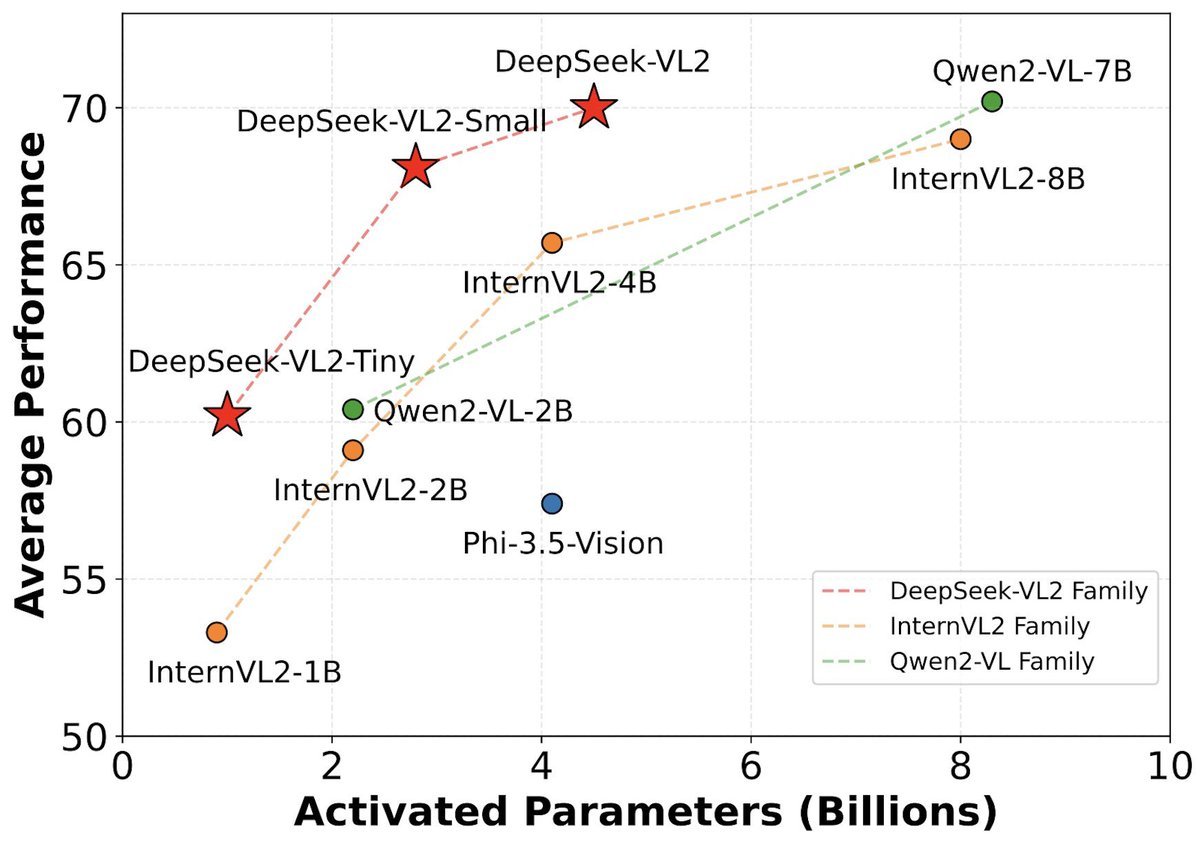
The model series includes three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small, and DeepSeek-VL2, featuring 1.0B, 2.8B, and 4.5B activated parameters, respectively. With competitive or state-of-the-art performance, DeepSeek-VL2 matches or surpasses existing open-source dense and MoE-based models while utilizing comparable or fewer activated parameters.
DeepSeek-VL2 Installation
On the basis of Python >= 3.8 environment, install the necessary dependencies by running the following command:
pip install -e .
Simple Inference Example
import torch
from transformers import AutoModelForCausalLM
from deepseek_vl.models import DeepseekVLV2Processor, DeepseekVLV2ForCausalLM
from deepseek_vl.utils.io import load_pil_images
# specify the path to the model
model_path = "deepseek-ai/deepseek-vl2-small"
vl_chat_processor: DeepseekVLV2Processor = DeepseekVLV2Processor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
vl_gpt: DeepseekVLV2ForCausalLM = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
## single image conversation example
conversation = [
{
"role": "<|User|>",
"content": "<image>\n<|ref|>The giraffe at the back.<|/ref|>.",
"images": ["./images/visual_grounding.jpeg"],
},
{"role": "<|Assistant|>", "content": ""},
]
## multiple images (or in-context learning) conversation example
# conversation = [
# {
# "role": "User",
# "content": "<image_placeholder>A dog wearing nothing in the foreground, "
# "<image_placeholder>a dog wearing a santa hat, "
# "<image_placeholder>a dog wearing a wizard outfit, and "
# "<image_placeholder>what's the dog wearing?",
# "images": [
# "images/dog_a.png",
# "images/dog_b.png",
# "images/dog_c.png",
# "images/dog_d.png",
# ],
# },
# {"role": "Assistant", "content": ""}
# ]
# load images and prepare for inputs
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(
conversations=conversation,
images=pil_images,
force_batchify=True,
system_prompt=""
).to(vl_gpt.device)
# run image encoder to get the image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
# run the model to get the response
outputs = vl_gpt.language_model.generate(
inputs_embeds=inputs_embeds,
attention_mask=prepare_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True
)
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)
DeepSeek-VL2 Paper
License
This code repository is licensed under MIT License. The use of DeepSeek VL2 models is subject to DeepSeek Model License. DeepSeek v2 series supports commercial use.
Read recent articles in our Blog: