
Mistral 12B NeMo is a state-of-the-art 12B model with 128k context length, built in collaboration with NVIDIA, and released under the Apache 2.0 license.
Today marks the release of Mistral NeMo, a new AI model developed by the Mistral team in collaboration with NVIDIA. Mistral NeMo, a 12B model, features a large context window of up to 128k tokens. It boasts state-of-the-art reasoning, world knowledge, and coding accuracy for its size category. With its reliance on standard architecture, Mistral NeMo is user-friendly and can be seamlessly integrated as a replacement in any system currently utilizing Mistral 7B.
To encourage adoption among researchers and enterprises, the team has released pre-trained base and instruction-tuned checkpoints under the Apache 2.0 license. Mistral NeMo was also trained with quantization awareness, allowing FP8 inference without any performance degradation.
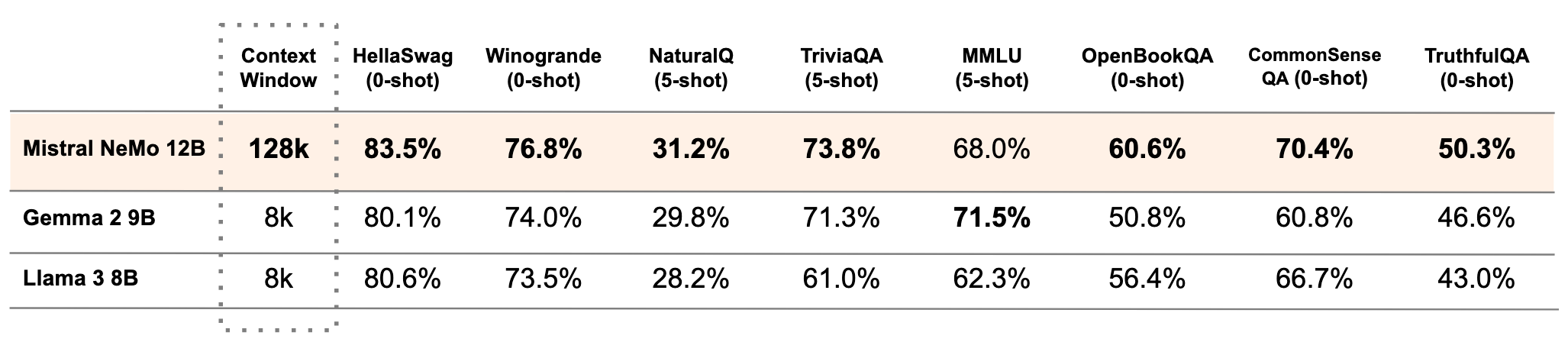
The following table compares the accuracy of the Mistral NeMo base model with two recent open-source pre-trained models, Gemma 2 9B, and Llama 3 8B.
Multilingual Model for the Masses
Mistral NeMo is designed for global, multilingual applications. It is trained on function calling, has a large context window, and excels in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi. This development represents a significant step toward making advanced AI models accessible in all languages that contribute to human culture.

Tekken: A More Efficient Tokenizer
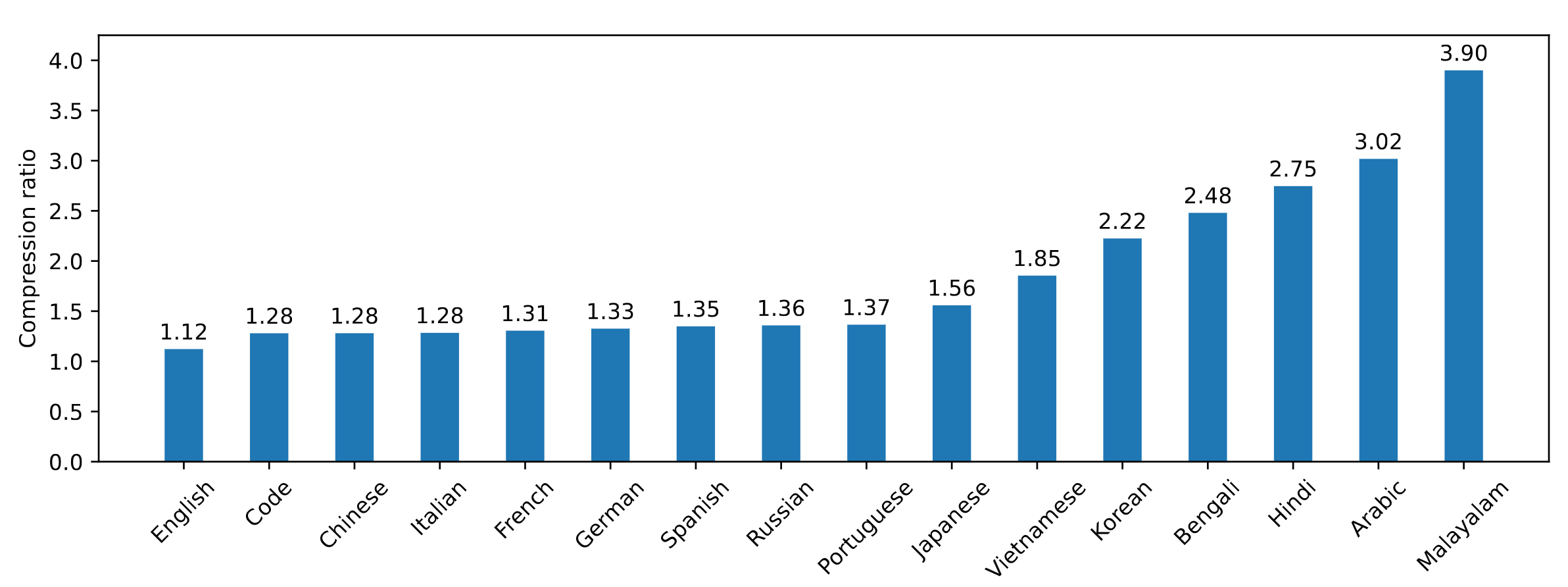
Mistral NeMo employs a new tokenizer, Tekken, based on Tiktoken. Trained on over 100 languages, Tekken compresses natural language text and source code more efficiently than the SentencePiece tokenizer used in previous Mistral models. It is approximately 30% more efficient at compressing source code, Chinese, Italian, French, German, Spanish, and Russian. For Korean and Arabic, it is 2x and 3x more efficient, respectively. Compared to the Llama 3 tokenizer, Tekken has proven to be more proficient in compressing text for about 85% of all languages.
Instruction Fine-tuning
Mistral NeMo underwent an advanced fine-tuning and alignment phase. Compared to Mistral 7B, it excels in following precise instructions, reasoning, handling multi-turn conversations, and generating code.

Links
Weights are hosted on HuggingFace both for the base and for the instruct models. You can try Mistral NeMo now with mistral-inference and adapt it with mistral-finetune. Mistral NeMo is exposed on la Plateforme under the name open-mistral-nemo-2407. This model is also packaged in a container as NVIDIA NIM inference microservice and available from ai.nvidia.com.
Read related articles: