OpenAI just announced ‘o3’, a breakthrough AI model that significantly surpasses all previous models in benchmarks.
- —On ARC-AGI: o3 more than triples o1’s score on low compute and surpasses a score of 87%
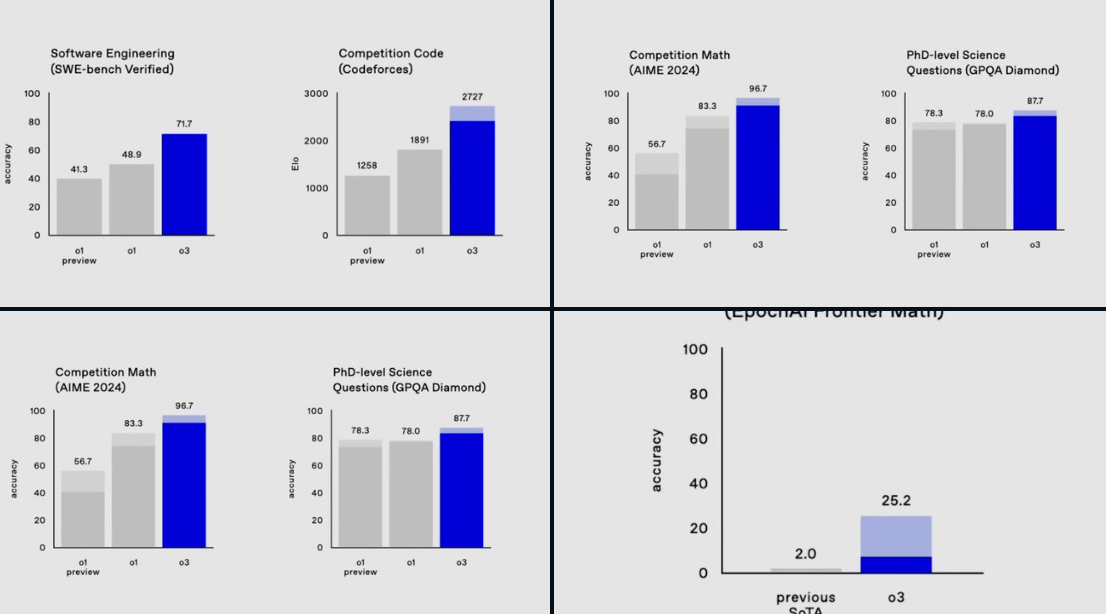
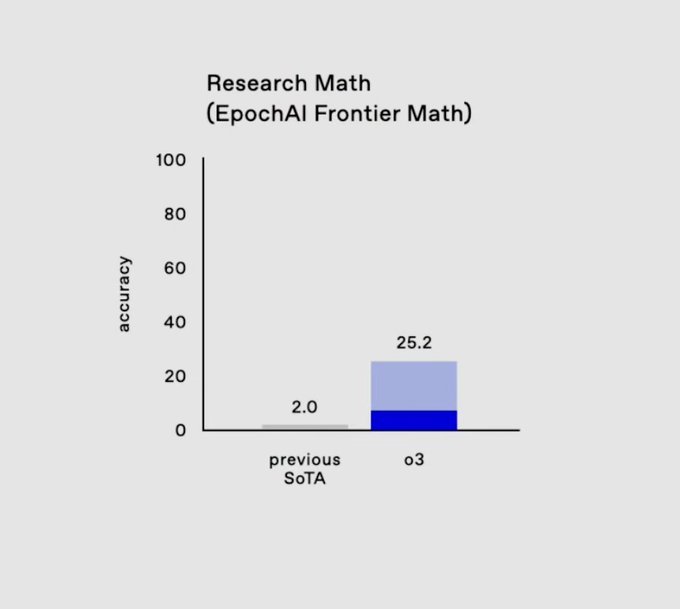
- —On EpochAI’s Frontier Math: o3 set a new record, solving 25.2% of problems, where no other model exceeds 2%
- —On SWE-Bench Verified: o3 outperforms o1 by 22.8 percentage points
- —On Codeforces: o3 achieved a rating of 2727, surpassing OpenAI’s Chief Scientist’s score of 2665
- —On AIME 2024: o3 scored 96.7%, missing only one question
- —On GPQA Diamond: o3 achieved 87.7%, well above human expert performance
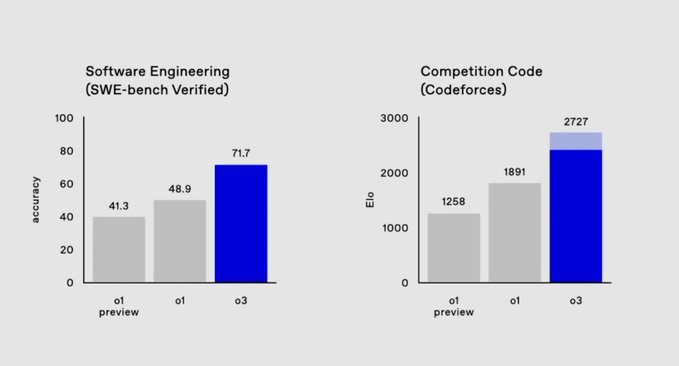
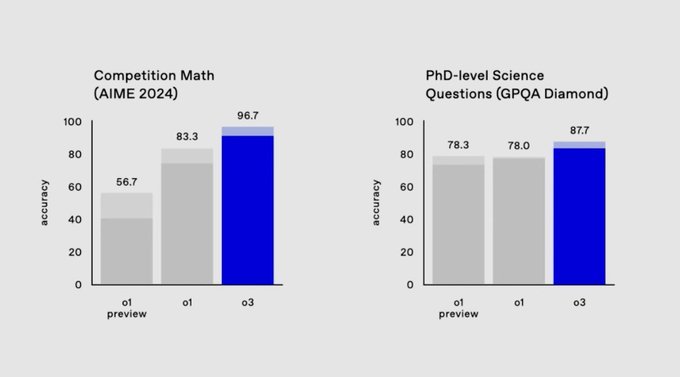
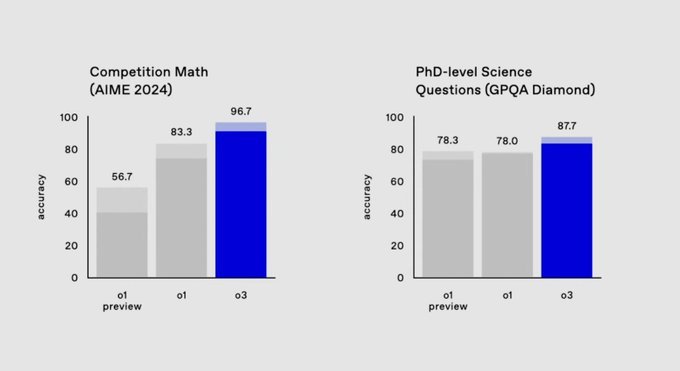
The OpenAI o3 model is in ‘preview’ and only open to safety and security researchers who apply through the link on their site. Recently, Sam Altman said there should be a federal testing framework to ensure safety before release, so the cautiousness makes sense.
Read related article sin our Blog.