
Last week, Meta FAIR released Meta Chameleon, a groundbreaking mixed-modal research model. This model is designed to handle both text and images seamlessly. Meta Chameleon is available in two variants: the 7B and 34B safety-tuned models.
Unified Architecture
Unlike many other large language models, Meta Chameleon uses a single unified architecture. This means it can process any combination of text and images as input.
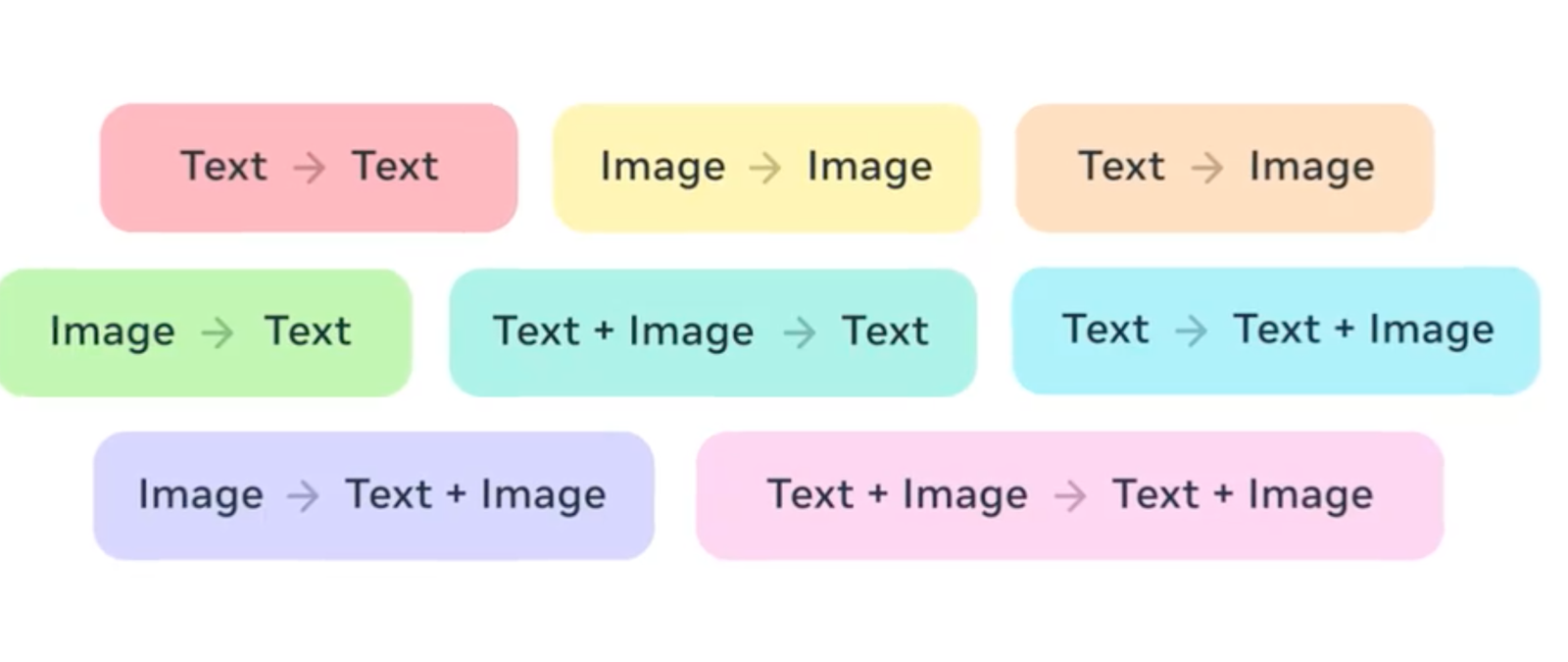
It then produces text outputs using a new early fusion approach. This is a significant departure from traditional models that use separate encoders or decoders for images and text.
Meta is releasing Chameleon models under a research license. This move aims to democratize access to foundational mixed-modal models. It also seeks to further research on early fusion techniques. By making these models accessible, Meta hopes to spur innovation and development in this field.
Capabilities and Performance
Chameleon is a family of early-fusion token-based mixed-modal models. These models are capable of understanding and generating images and text in any arbitrary sequence. The training approach is stable from inception. It includes an alignment recipe and architectural parameterization tailored for the early-fusion, token-based, mixed-modal setting.
The models have been evaluated on a comprehensive range of tasks. These include visual question answering, image captioning, text generation, image generation, and long-form mixed-modal generation. Chameleon demonstrates broad and general capabilities. It achieves state-of-the-art performance in image captioning tasks. Also, the model outperforms Llama-2 in text-only tasks. It is competitive with models such as Mixtral 8x7B and Gemini-Pro.
Image and Text Generation
Chameleon performs non-trivial image generation, all within a single model. It matches or exceeds the performance of much larger models, including Gemini Pro and GPT-4V. This is according to human judgments on a new long-form mixed-modal generation evaluation. In this evaluation, either the prompt or outputs contain mixed sequences of both images and text.
A Significant Step Forward
Chameleon marks a significant step forward in the unified modeling of full multimodal documents. It brings together the capabilities of image and text generation in a single, cohesive model. This unified approach is poised to drive further advancements in the field of AI.
Access the Model
To explore and utilize Meta Chameleon, visit the official Meta AI resources page.
Meta Chameleon represents a leap forward in AI capabilities. Its unified architecture and comprehensive evaluation showcase its potential. It is set to be a valuable tool for researchers and developers alike.
Read related articles: