
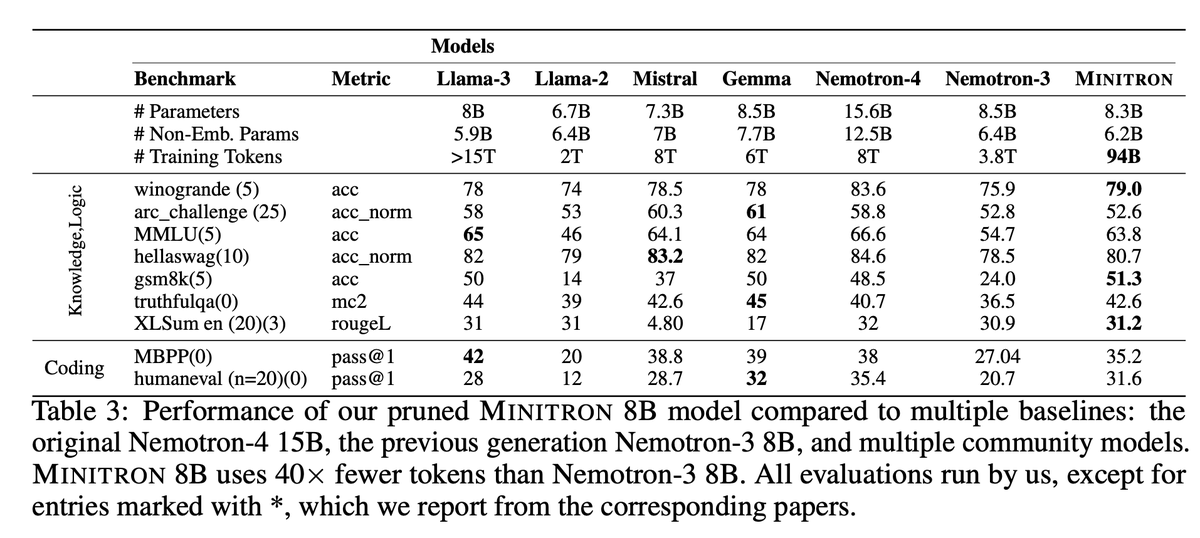
Nvidia releases Minitron 4B & 8B – iteratively pruning and distilling 2-4x smaller models from large LLMs, requiring 40x fewer training tokens and with 16% improvement on MMLU!
Distilled model (w/ pruning + retraining) beats teacher!
- Competitive with L3 8B/ Mistral 7B with fractional compute + training tokens.
- 94B training tokens only.
- 256K vocab.
- Integrated with transformers.
Best practices:
- Train a big LLM, iteratively prune + distil + retrain.
- Use KL Divergence as the loss function for distillation.
- Logit loss is sufficient for retraining/ distilling, so there is no need for CLM loss.
- Iterative (instead of one-shot) pruning results in the student model outperforming the teacher.
- Depth + Width pruning results in the best performance.
- Lightweight Neural Architecture Search for distilled checkpoints.
And many more in the paper below.
Minitron 8B Base
Minitron is a family of small language models (SLMs) obtained by pruning NVIDIA’s Nemotron-4 15B model. We prune model embedding size, attention heads, and MLP intermediate dimension, following which, we perform continued training with distillation to arrive at the final models.
Deriving the Minitron 8B and 4B models from the base 15B model using our approach requires up to 40x fewer training tokens per model compared to training from scratch; this results in compute cost savings of 1.8x for training the full model family (15B, 8B, and 4B). Minitron models exhibit up to a 16% improvement in MMLU scores compared to training from scratch, perform comparably to other community models such as Mistral 7B, Gemma 7B and Llama-3 8B, and outperform state-of-the-art compression techniques from the literature.
Minitron models are for research and development only.
Minitron 8B Paper
Download
A family of compressed models obtained via pruning and knowledge distillation, available on HuggingFace:
The Company released the base checkpoints for both 8B and 4B; it would be cool to see the instruct checkpoints, too!
Kudos Nvidia!
Read related articles: